
Meta, en son açık kaynaklı yapay zeka modelini duyurdu ve bu model şimdiye kadarki en büyüklerinden biri. Llama 3.1 405B olarak adlandırılan bu model, 405 milyar parametre içeriyor. Parametreler, bir modelin problem çözme becerilerine yaklaşık olarak denk gelir ve daha fazla parametreye sahip modeller, genellikle daha az parametreye sahip olanlardan daha iyi performans gösterir.
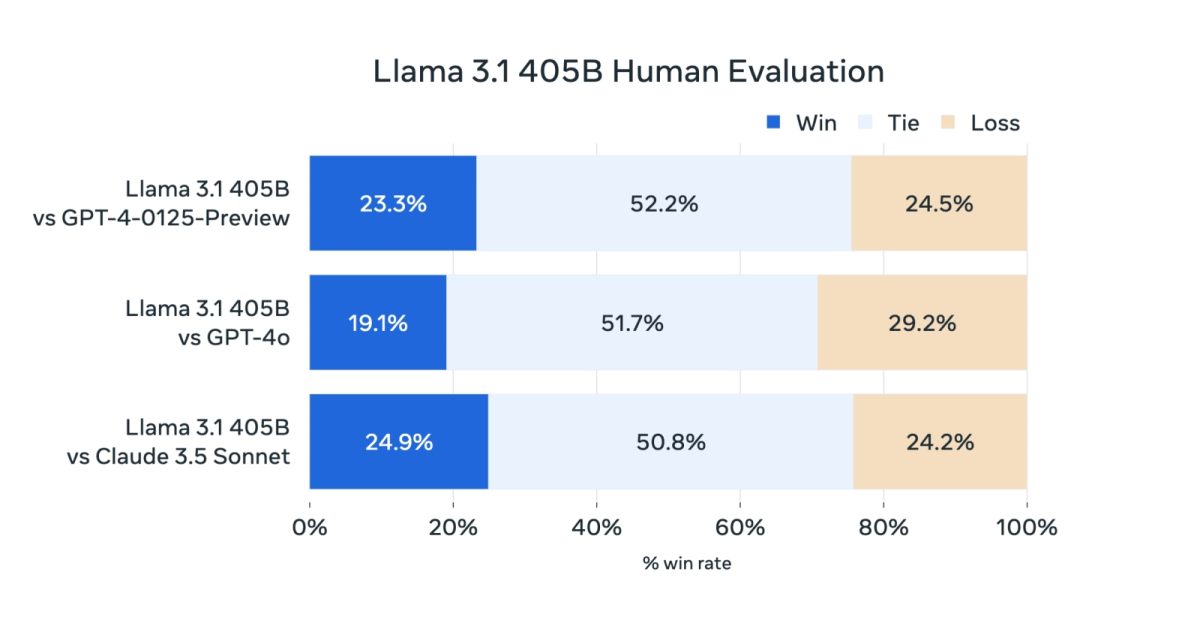
405 milyar parametreye sahip olan Llama 3.1 405B, açık kaynak dünyasında mutlak anlamda en büyük model olmasa da, son yıllarda çıkan en büyük modellerden biri. 16.000 Nvidia H100 GPU kullanılarak eğitilen bu model, Meta’nın iddiasına göre, en son eğitim ve geliştirme teknikleriyle, OpenAI’ın GPT-4o ve Anthropic’in Claude 3.5 Sonnet gibi önde gelen tescilli modellerle rekabet edebilecek düzeyde (bazı istisnalar hariç).
Yeni ve Geliştirilmiş Özellikler
Llama 3.1 405B, kodlama ve temel matematik sorularını yanıtlamaktan, sekiz farklı dilde (İngilizce, Almanca, Fransızca, İtalyanca, Portekizce, Hintçe, İspanyolca ve Tayca) belgeleri özetlemeye kadar çeşitli görevleri yerine getirebiliyor. Bu model yalnızca metin tabanlıdır, yani bir görüntü hakkında soruları yanıtlayamaz, ancak metin tabanlı iş yüklerinin çoğunu – PDF ve elektronik tablo gibi dosyaları analiz etmek gibi – gerçekleştirebilir.
Meta, çok modlulukla (multimodality) denemeler yaptığını belirtmek istiyor. Bugün yayınlanan bir makalede, şirketin araştırmacıları, görüntüleri ve videoları tanıyabilen ve konuşmayı anlayabilen (ve üretebilen) Llama modelleri geliştirdiklerini yazıyorlar. Ancak, bu modeller henüz kamuya açık hale getirilmek için hazır değil.
Eğitim Verisi ve Yapay Veri Kullanımı
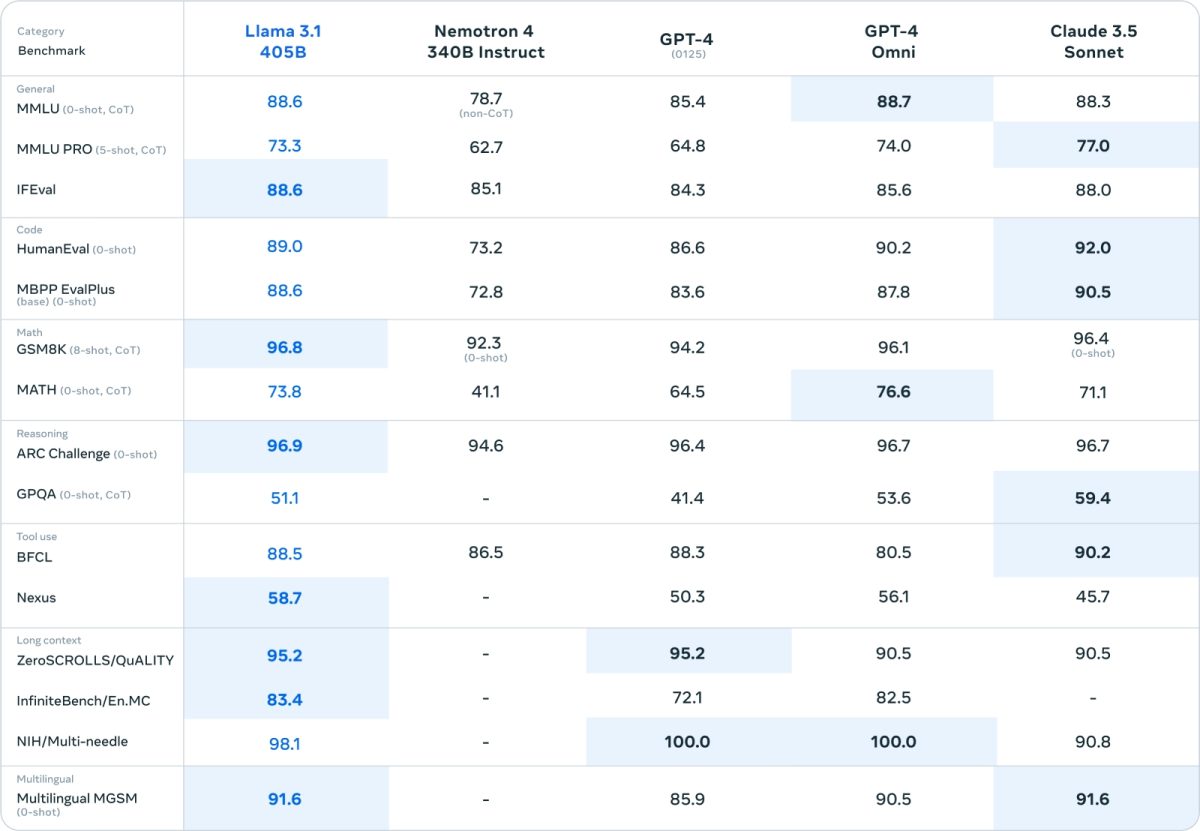
Llama 3.1 405B’yi eğitmek için Meta, 2024’e kadar uzanan 15 trilyon tokenlik bir veri seti kullandı. Tokenler, modellerin daha kolay içselleştirebileceği kelime parçalarıdır ve 15 trilyon token, yaklaşık 750 milyar kelimeye tekabül eder. Bu, tamamen yeni bir eğitim seti değil, çünkü Meta, önceki Llama modellerini eğitmek için de bu temel seti kullandı, ancak şirket, veri için kürasyon hatlarını daha iyi hale getirdiğini ve modelin geliştirilmesinde “daha titiz” kalite güvence ve veri filtreleme yaklaşımlarını benimsediğini iddia ediyor.
Meta ayrıca Llama 3.1 405B’yi ince ayar yapmak için yapay veri (diğer AI modelleri tarafından üretilen veri) kullandı. OpenAI ve Anthropic gibi büyük AI satıcılarının çoğu, AI eğitimlerini ölçeklendirmek için yapay verilerin uygulamalarını araştırıyor, ancak bazı uzmanlar, yapay verinin model önyargısını artırma potansiyeli nedeniyle son çare olarak kullanılması gerektiğine inanıyor. Meta, Llama 3.1 405B’nin eğitim verilerini “dikkatle dengelediğini” iddia etse de, verilerin tam olarak nereden geldiğini açıklamaktan kaçındı (web sayfaları ve halka açık web dosyaları dışında). Birçok üretken AI satıcısı, eğitim verilerini rekabet avantajı olarak gördüğü için bu bilgileri gizli tutar.
Meta araştırmacıları, önceki Llama modellerine kıyasla, Llama 3.1 405B’nin, daha fazla İngilizce olmayan veri (diğer dillerdeki performansını artırmak için), daha fazla “matematiksel veri” ve kod (modelin matematiksel akıl yürütme becerilerini geliştirmek için) ve daha yeni web verileri (güncel olaylar hakkındaki bilgisini artırmak için) ile eğitildiğini yazdı.
Reuters tarafından yapılan son haberlerde, Meta’nın AI eğitiminde telif hakkıyla korunan e-kitapları kendi avukatlarının uyarılarına rağmen kullandığı ortaya çıktı. Şirketin, Instagram ve Facebook gönderileri, fotoğraflar ve başlıkları üzerinde eğitim yaptığı ve kullanıcıların bu durumdan çıkış yapmasını zorlaştırdığı belirtiliyor. Ayrıca, Meta ve OpenAI, yazarların (aralarında komedyen Sarah Silverman da dahil) telif hakkıyla korunan verileri izinsiz kullanmakla ilgili açtığı davanın konusudur.
Daha Büyük Bağlam ve Araçlar
Llama 3.1 405B, önceki Llama modellerinden daha büyük bir bağlam penceresine sahiptir: 128.000 token, yani yaklaşık 50 sayfalık bir kitabın uzunluğu. Bir modelin bağlamı, modelin çıktı üretmeden önce dikkate aldığı girdi verilerini (örneğin metin) ifade eder.
Daha büyük bağlamlara sahip modellerin avantajlarından biri, daha uzun metin parçalarını ve dosyaları özetleyebilmeleridir. Sohbet botlarını desteklerken, bu modellerin yakın zamanda tartışılan konuları unutma olasılığı da daha düşüktür.
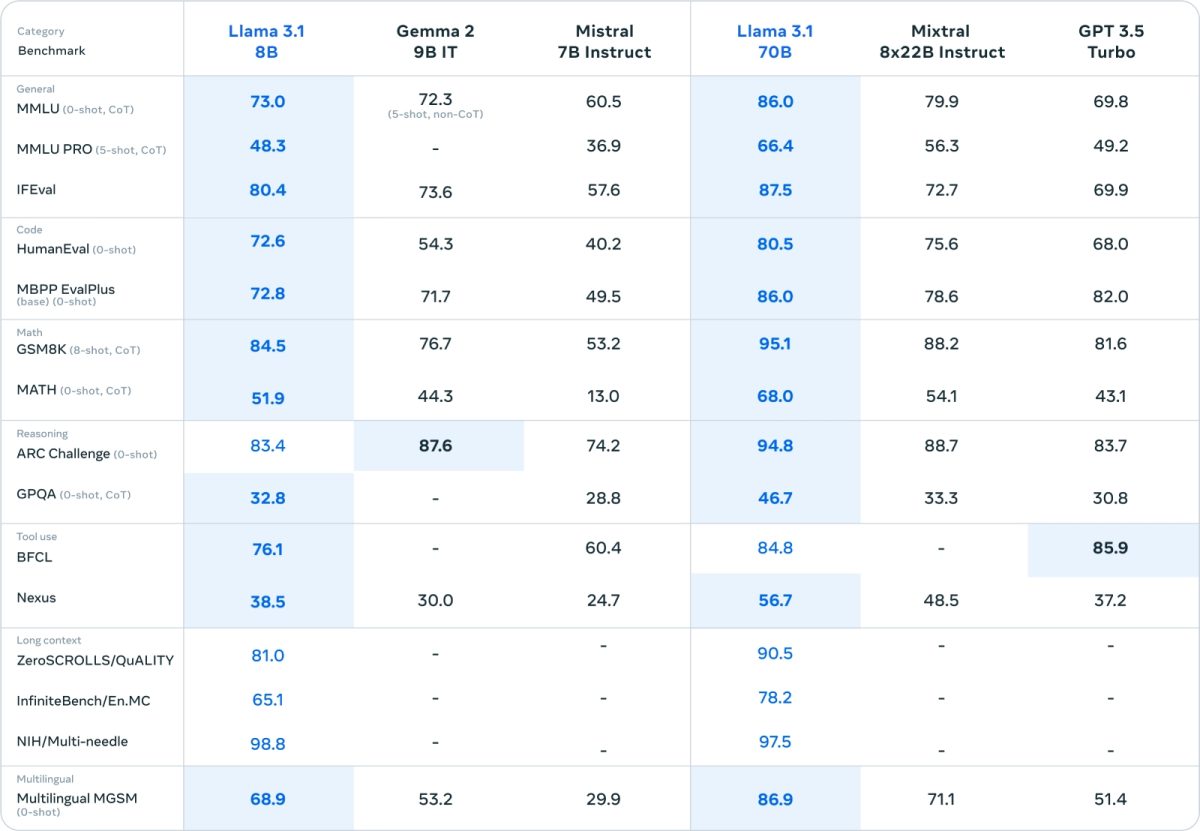
Meta’nın bugün tanıttığı diğer iki yeni, daha küçük model olan Llama 3.1 8B ve Llama 3.1 70B — Nisan ayında piyasaya sürülen Llama 3 8B ve Llama 3 70B modellerinin güncellenmiş versiyonları — da 128.000 token bağlam pencerelerine sahiptir. Önceki modellerin bağlamı 8.000 token ile sınırlıydı, bu da bu yükseltmenin oldukça önemli olduğu anlamına gelir – yeni Llama modellerinin tüm bu bağlam boyunca etkili bir şekilde akıl yürütebildiğini varsayarsak.
Tüm Llama 3.1 modelleri, diğer araçlar, uygulamalar ve API’lar kullanarak görevleri tamamlayabilir, tıpkı Anthropic ve OpenAI’nin rakip modelleri gibi. Kutudan çıktığı haliyle, Brave Search’u kullanarak son olaylar hakkında soruları yanıtlamak, Wolfram Alpha API’sini matematik ve bilimle ilgili sorgular için kullanmak ve kodu doğrulamak için bir Python yorumlayıcısı kullanmak üzere eğitildiler. Ayrıca, Meta, Llama 3.1 modellerinin daha önce görmedikleri belirli araçları bir dereceye kadar kullanabileceklerini iddia ediyor.